Ningún investigador puede leer todos los artículos y trabajos que se publican en su campo. Los ordenadores, en cambio, sí. Gracias a las asombrosas capacidades de cálculo y procesamiento de datos de los nuevos superordenadores, las máquinas están haciendo sus propios descubrimientos, utilizando la minería de datos para analizar toda la literatura científica existente. En este artículo, averigurás más cosas acerca algunos de estos superordenadores.

Supercomputadora KnIt: nuevos medicamentos sobre el cáncer
En mayo del año pasado, una supercomputadora en San José, California, leyó 100.000 artículos de investigación en 2 horas. Se encuentra nueva biología oculta en los datos. Esta computadora llamada KnIT es uno de los pocos sistemas que empujan las fronteras del conocimiento sin la ayuda humana.
KnIT no lee los periódicos como un científico. Esto le habría tomado yoda la vida. En su lugar, se escanea toda la información en busca de una proteína llamada p53 , y una clase de enzimas que pueden interactuar con ella, llamadas quinasas. También conocida como «el guardián del genoma», la p53 suprime tumores en los seres humanos. KnIt rastreó la literatura en busca de enlaces que impliquen quinasas p53 no descubiertas, que podrían proporcionar caminos para nuevos medicamentos contra el cáncer.
Habiendo analizado todos los documentos hasta 2003, KnIt identificó siete de las nueve quinasas descubiertas durante los siguientes 10 años. Más importante aún, también encontró lo que parecían ser dos p53 quinasas desconocidas para la ciencia. Pruebas de laboratorio iniciales confirmaron los hallazgos, aunque el equipo quiere repetir el experimento para estar seguro.
La supercomputadora KnIt es producto de una colaboración entre IBM y el Baylor College of Medicine en Houston, Texas. Es el último paso en un mundo extraño donde las máquinas autónomas hacen descubrimientos que van más allá de los científicos, simplemente rebuscando más a fondo a través de lo que ya sabemos, y más rápido que lo que cualquier humano podría.
En un documento que se presentará en la Conference on Knowledge Discovery and Data Mining en la ciudad de Nueva York esta semana, los investigadores dicen que la sociedad es mejor en la generación de nueva información que en el análisis de lo que ya tiene. «Esto conduce a ineficiencias profundas a la hora de traducir la investigación en progreso para la humanidad». KnIt pretende superar esta ineficiencia.
«En general, las nuevas quinasas p53 se descubren a un ritmo de una por año», dice Olivier Lichtarge, quien dirige el trabajo en Baylor. «Esperamos poder acelerar en gran medida la tasa de descubrimiento».
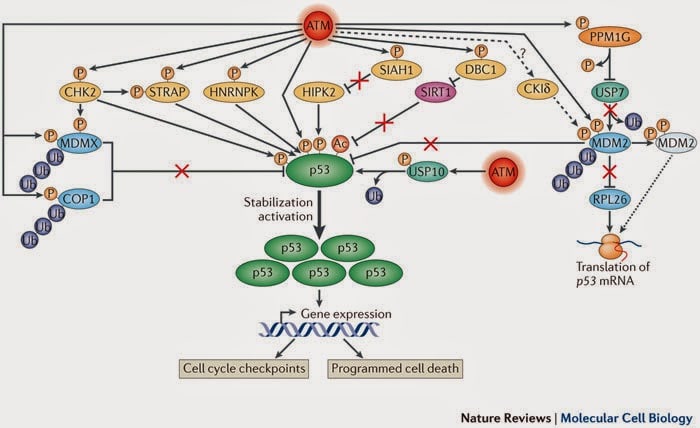
Imagen: Nature
¿Se puede extender la actividad de KnIt a otras áreas de la ciencia?
Estudiar quinasas es importante para la investigación del cáncer, pero el equipo de Baylor piensa que este enfoque puede extenderse más allá de los estudios biomédicos a todas las áreas de la ciencia. Y si los descubrimientos algorítmicos de KnIt se mantienen, veríamos un futuro en el que todo el mundo podría tener un algoritmo personalizado y dar sentido a la literatura científica para averiguar la cura de sus dolencias, incluidas las adaptadas a su nivel genético.
Ampliarlo a otras áreas de la biología o las ciencias físicas no es sencillo. «Podríamos correr grandes problemas cuando tratamos de generalizar a más proteínas y genes», dice Lichtarge. Y en temas como la física, los resultados tienden a ser presentado utilizando ecuaciones y gráficos en lugar de palabras. Sin embargo, los grupos de minería de datos están trabajando para recuperar información también de estos campos.
Imagen: echathon.mytechlabs.com
La idea de que el nuevo conocimiento puede ser descubierto mediante la búsqueda de vínculos entre hebras dispares de la investigación se cristalizó primera vez en 1986 por el científico de la información Don Swanson de la Universidad de Chicago. Se analizó una base de datos de la literatura científica manualmente para deducir que el aceite de pescado podría ser un buen tratamiento para el síndrome de Raynaud, un trastorno circulatorio, ya que los estudios mostraron que el aceite de pescado podría revertir ciertas condiciones que también se observaban en la enfermedad de Raynaud. Su presentimiento resultó ser correcto.
Los avances de otras supercomputadoras (Eve, Facta+..) ¿pueden ser útiles a los usuarios no científicos?
La ciencia moderna nos ha dado «un pajar» enorme y complejo, pero la inteligencia de las máquinas intenta moverse a través de él para clasificar y encontrar nuevas conexiones.
Ross King, de la Universidad de Manchester, Reino Unido, ha desarrollado un tipo diferente de sistema automatizado, Eve que, según él, ya ha descubierto un nuevo fármaco contra la malaria. En lugar de extraer nuevos conocimientos a partir de la literatura, Eve lleva a cabo robóticamente experimentos de laboratorio centrados en la búsqueda de nuevos fármacos para tratar enfermedades olvidadas. King mantendrá en secreto el descubrimiento hasta que se publique la obra, pero se dice que el compuesto es un ingrediente contenido en varias marcas de pasta de dientes.
Las redes de conocimiento que los ordenadores crean en esta búsqueda automatizada de descubrimientos son útiles también para los no científicos. Sophia Ananiadou en la Universidad de Manchester trabaja en Facta +, una base de datos que contiene enormes cantidades de información sobre el cáncer, basados en datos extraídos de la literatura científica.

Sophia Ananiadou
Aunque está diseñado para ayudar a los investigadores del cáncer, dice que podría ser utilizado por el público en general para aprender más acerca de las enfermedades que han sido diagnosticadas, sin tener que leer artículos científicos mismos.
Modelos computacionales de células que se pueden utilizar para probar los medicamentos
Al propósito de la minería de datos también puede darsele la vuelta. En lugar de encontrar nuevas perspectivas sobre temas especializados, los sistemas como Knit pueden encontrar agujeros en la investigación existente que necesitan ser conectados.
Natasa Miskov-Živanov de la Universidad Carnegie Mellon, Pittsburgh, está trabajando en el uso de técnicas similares para construir modelos computacionales de células que se pueden utilizar para probar los medicamentos. Normalmente, los modelos se tarda tiempo en desarrollarlos, con la participación de biólogos experimentales y teóricos. Pero los modelos de Miskov-Živanov se construuen ellos mismos de forma rápida y automática utilizando los resultados de la literatura existente. Los modelos pueden ser probados por los científicos en el laboratorio.

Natasa Miskov-Živanov
El trabajo de Miskov-Živanov es financiado por la Agencia de Defensa de Estados Unidos DARPA como parte de Big Mechanism project, que tiene como objetivo encontrar nuevos conocimientos ocultos en los grandes datos.
«Se necesitan varios años para desarrollar un modelo significativo de lo que está pasando en una célula, pero lo que estamos haciendo podría acelerar mucho el proceso», dice. «Eso, a su vez, acelera las pruebas de medicamentos».
Nuevos avances podrían llegar mediante el análisis de la literatura científica en todas las disciplinas – la física a escala de las células y la biología molecular, por ejemplo.
«No creo que pudiéramos entender nunca este enorme y complicado rompecabezas sin ayuda automatizada», dice King. «Simplemente no hay suficientes doctores en el mundo para hacer los experimentos.»
Fuente: New Scientist, 27 de agosto 2014, por Hal Hodson.
Seguir leyendo:
- Un nuevo sistema informático del MIT podría automatizar por completo el análisis de los Big Data
- La supercomputadora Watson se abre: nos dará respuestas a través de sus enormes archivos
- Google anuncia que su ordenador cuántico funciona
- Cómo están utilizando la inteligencia artificial las grandes empresas